
Like Binary Search, Jump Search is a scanning calculation for arranged clusters. The fundamental thought is to check fewer components (than direct hunt) by hopping ahead by fixed advances or skirting a few components instead of looking through all components.
For instance, assume we have an array arr[] of size n and square (to be hopped) size m. At that point we search at the records arr[0], arr[m], arr[2m]… ..arr[km], etc. When we discover the stretch (arr[km] < x < arr[(k+1)m]), we play out a straight pursuit activity from the file km to discover the component x.
How about we think about the accompanying array: (0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610). Length of the cluster is 16. Bounce search will discover the estimation of 55 with the accompanying advances expecting that the square size to be hopped is 4.
- Stage 1: Go from index 0 to index 4
- Stage 2: Go from index 4 to index 8
- Stage 3: Go from index 8 to index 12
- Stage 4: Since the component at a record 12 is more prominent than 55 we will bounce back a stage to come to list 8
- Stage 5: Perform straight pursuit from list 8 to get the component 55.
What is the ideal square size to be skipped?
In the most pessimistic scenario, we need to do n/m hops and if the last checked worth is more prominent than the component to be looked for, we perform m-1 correlations more for straight hunt. In this way the absolute number of examinations in the most pessimistic scenario will be ((n/m) + m-1). The estimation of the capacity ((n/m) + m-1) will be least when m = √n. In this manner, the best advance size is m = √n.
Implementation of Jump Search Algorithm:
In this program we have implemented the Jump search algorithm in C++ language:
#include<iostream>
#include<cmath>
using namespace std;
int jumpSearch(int a[], int n, int item) {
int i = 0;
int m = sqrt(n); //initialise the block size= √(n)
while(a[m] <= item && m < n) { // the control will continue to jump the blocks i = m; // shift the block m += sqrt(n); if(m > n – 1) // if m exceeds the array size
return -1;
}
for(int x = i; x<m; x++) { //linear search in current block
if(a[x] == item)
return x; //position of element being searched
}
return -1;
}
int main() {
int n, item, loc;
cout << “\n Enter number of items: “; cin >> n;
int arr[n]; //creating an array of size n
cout << “\n Enter items: “;
for(int i = 0; i< n; i++) { cin >> arr[i];
}
cout << “\n Enter search key to be found in the array: “; cin >> item;
loc = jumpSearch(arr, n, item);
if(loc>=0)
cout << “\n Item found at location: ” << loc;
else
cout << “\n Item is not found in the list.”;
}
The input array is the same as that we have used in the example:
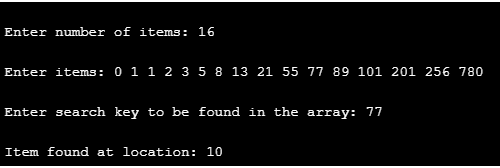
Note: The calculation can be actualised in any programming language according to the necessity.
Multifaceted nature Analysis for Jump Search
We should perceive what will be the reality intricacy for the Jump search calculation:
Time Complexity:
The while circle in the above C++ code executes n/m times on the grounds that the circle counter augmentations by m times in each emphasis. Since the ideal estimation of m= √n , in this manner, n/m=√n bringing about a period intricacy of O(√n).
Space Complexity:
The space intricacy of this calculation is O(1) since it doesn’t require any other information structure for its usage.
Key points to recollect about Jump Search Algorithm
- This calculation works just for arranged info exhibits.
- The ideal size of the square to be skipped is √n, hence bringing about the time multifaceted nature O(√n2).
- The time multifaceted nature of this calculation lies in the middle of straight pursuit (O(n)) and parallel hunt (O(log n)).
It is likewise called block search calculation
Binary Search is superior to Jump Search, however, Jump search has a preferred position that we navigate back just a single time (Binary Search may require up to O(Log n) bounces, believe a circumstance where the component to be looked is the littlest component or littler than the littlest). So in a framework where a paired hunt is exorbitant, we use Jump Search.
Preferences of Jump Search Algorithm: It is quicker than the straight hunt strategy which has a period multifaceted nature of O(n) for looking through a component.
Disservices of Jump Search Algorithm: It is slower than double inquiry calculation which looks through a component in O(log n). It requires the info exhibit to be arranged.
To read more about Data Structures, click here.
By Akhil Sharma







